引言:从2D到3D的瓶颈
在计算机视觉和图形学中,如何从一组稀疏的2D图像中重建出连续、逼真的3D场景,一直是一个核心挑战。传统方法如多视图立体视觉或基于体素/点云的表示,往往在细节、连续性和渲染质量上存在局限。
2020年,一篇名为《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》的论文提出了一种全新的思路,彻底改变了这一领域。它不再显式地存储3D几何,而是用一个神经网络来隐式地学习整个场景的“辐射场”。

图1: NeRF模型输入稀疏图像(左)后,能够合成出任意新视角的高质量图像(右)。来源:NeRF论文
核心概念:什么是NeRF?
神经辐射场(Neural Radiance Field, NeRF)的核心思想非常优雅:它将一个连续的3D场景表示为一个参数化的函数,这个函数由一个多层感知机(MLP)来近似。
这个函数做了什么?对于3D空间中的任意一个点 `(x, y, z)` 和观察这个点的方向 `(θ, φ)`,NeRF模型会预测两件事:
- 体积密度 (σ):这个点的不透明度或“存在物质”的概率。它只与位置有关,与视角无关。
- 颜色 (RGB):从这个点沿特定方向发出的光线的颜色。它同时依赖于位置和视角,以模拟镜面反射等视角相关效果。
其中,\( \mathbf{x} = (x, y, z) \) 是空间坐标,\( \mathbf{d} = (\theta, \phi) \) 是视角方向,\( \mathbf{c} = (r, g, b) \) 是颜色,\( \sigma \) 是密度,\( \Theta \) 是神经网络的参数。
场景表示:隐式函数之美
与显式存储网格顶点或点云不同,NeRF是一种隐式场景表示。它没有直接存储3D几何,而是存储了一个可以查询任何位置属性的“规则”。
优缺点
- 优点:
- 高分辨率与连续性:理论上可以表示无限分辨率的场景,输出是连续的,没有离散化伪影。
- 内存高效:只需存储网络权重,而非庞大的3D体素网格。
- 自然平滑:神经网络作为连续函数,天生具有平滑先验,能生成视觉上愉悦的结果。
- 缺点:
- 渲染速度慢:合成一张新图需要查询数以万计的空间点,并进行数值积分,非常耗时。
- 训练成本高:每个场景都需要从头训练一个独立的模型。
- 编辑困难:修改隐式表示内的特定物体比修改显式网格要困难得多。
体积渲染:从密度到像素
我们知道了每个点的颜色和密度,如何得到一张2D图像中的一个像素颜色呢?NeRF使用了经典的体积渲染技术。
过程如下:从相机中心发射一条射线穿过该像素,沿着射线在深度范围内采样一系列点。每个采样点通过NeRF网络得到颜色和密度。最终像素的颜色是这些采样点颜色的加权和,权重由各点的密度(决定光线被阻挡的程度)累积计算得出。
其中,\( T(t) = \exp\left(-\int_{t_n}^{t} \sigma(\mathbf{r}(s)) ds\right) \) 是累积透射率,表示光线从起点 \( t_n \) 到达 \( t \) 而未被吸收的概率。
在代码中,这个积分通过离散采样来近似:
def volume_rendering(rgb, sigma, t_vals):
# rgb, sigma: 沿射线的采样点的颜色和密度 [n_rays, n_samples, 3], [n_rays, n_samples, 1]
# t_vals: 采样点的深度值 [n_rays, n_samples]
delta = t_vals[..., 1:] - t_vals[..., :-1] # 计算采样间隔
# 计算累积透射率 T_i
alpha = 1 - torch.exp(-sigma * delta) # 每个间隔的不透明度
T = torch.cumprod(1 - alpha + 1e-10, dim=-1) # 累积乘积
T = torch.cat([torch.ones_like(T[..., :1]), T[..., :-1]], dim=-1)
# 计算最终像素颜色(加权和)
weights = T * alpha
pixel_color = torch.sum(weights[..., None] * rgb, dim=-2)
return pixel_color训练过程:优化与技巧
训练一个NeRF模型需要一组已知相机位姿的场景图像。过程是直观的:
- 对于训练图像中的每个像素,根据相机参数生成对应的射线。
- 沿射线采样点,输入到MLP中得到预测的颜色和密度。
- 通过体积渲染公式合成预测的像素颜色。
- 计算预测颜色与真实像素颜色之间的误差(如L2损失)。
- 通过反向传播优化神经网络参数 \( \Theta \)。
一个关键的技巧是分层采样:先均匀粗采样整个射线,根据粗采样得到的密度分布(哪些区域更可能包含物体),再在重要区域进行二次精细采样。这大大提升了渲染质量和效率。
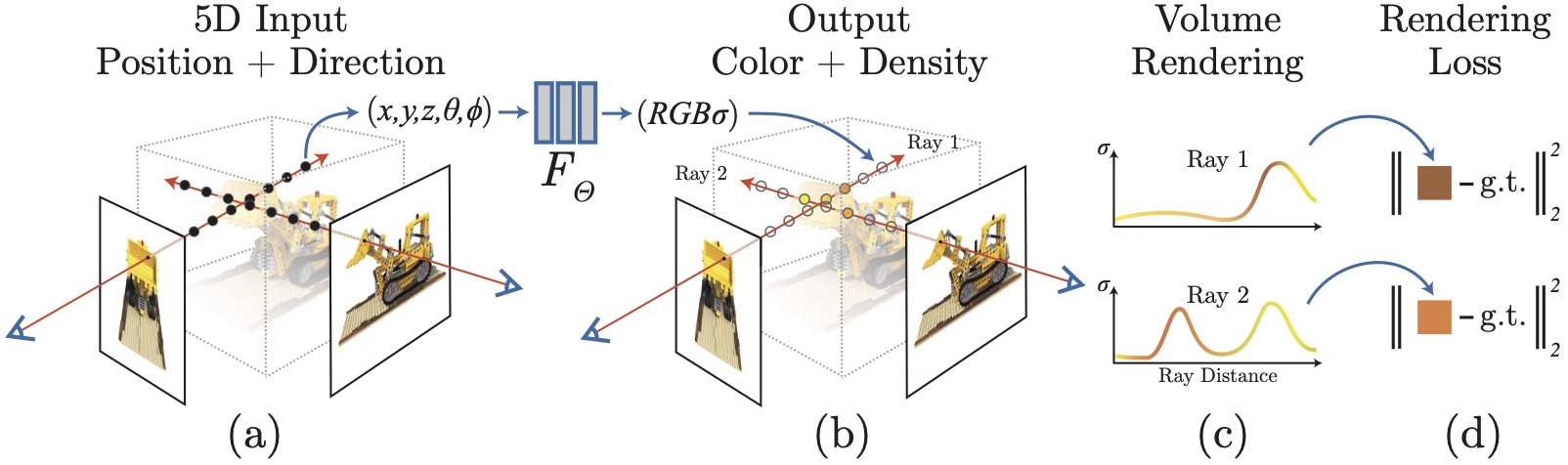
图2: NeRF训练与渲染流程示意图。展示了从输入图像和位姿,到沿射线采样,通过MLP查询,最后体积渲染合成图像的过程。来源:NeRF官方GitHub
位置编码:捕捉高频细节
研究者发现,直接将坐标 `(x,y,z)` 输入MLP,网络倾向于学习过于平滑的低频函数,导致结果模糊,丢失纹理细节。为了解决这个问题,NeRF使用了位置编码。
位置编码将低维输入映射到高维空间,使用正弦和余弦函数的不同频率:
这样,网络就能更容易地拟合场景中的高频变化(如边缘、纹理)。
import torch
import torch.nn as nn
import numpy as np
class PositionalEncoder(nn.Module):
def __init__(self, L=10):
super().__init__()
self.L = L
def forward(self, x):
# x: [..., input_dim]
encoded = [x]
for i in range(self.L):
encoded.append(torch.sin(2**i * np.pi * x))
encoded.append(torch.cos(2**i * np.pi * x))
return torch.cat(encoded, dim=-1)
# 示例:将3D坐标编码为更高维度
encoder = PositionalEncoder(L=10)
coords_3d = torch.randn(100, 3) # 100个3D点
encoded_coords = encoder(coords_3d) # 形状变为 [100, 3 + 2*10*3 = 63]应用与展望
自NeRF提出以来,它已催生了一个庞大的研究领域,并衍生出许多改进和变体:
- 实时NeRF:如Plenoxels, Instant-NGP,通过哈希网格、张量分解等技术将渲染速度提升数个数量级,达到实时或交互速率。
- 动态NeRF:处理动态场景和视频,将时间作为第四维输入。
- 生成式NeRF:将NeRF与生成对抗网络(GAN)结合,从无到有生成3D场景。
- 大规模场景NeRF:将场景分解为区块或使用更高效的表示来处理城市级别的场景。
其应用场景广泛,包括:
- 虚拟现实与增强现实:创建逼真的虚拟环境或将虚拟物体无缝融入真实世界。
- 文化遗产数字化:高保真地保存和展示文物、古迹。
- 电影与游戏:快速生成高质量的新视角,用于特效预览或内容创作。
- 机器人视觉:为机器人提供对环境的精细3D理解。
结论
神经辐射场(NeRF)以其简洁而强大的思想,为3D视觉领域开辟了一条新路径。它证明了用一个紧凑的神经网络隐式地表示复杂3D场景的可行性,并能实现前所未有的渲染质量。
尽管在速度、泛化能力和可编辑性上仍面临挑战,但后续层出不穷的改进工作正在迅速推动边界。NeRF不仅是一个强大的工具,更是一种新的范式,它启示我们重新思考如何用神经网络来表征和理解我们身处的三维世界。对于AI爱好者而言,理解NeRF是窥见下一代计算机视觉与图形学融合趋势的一扇重要窗口。