引言:从2D到3D的桥梁
传统的3D重建技术,如多视图立体几何(MVS)或结构光扫描,通常依赖于复杂的几何计算和硬件设备,且重建结果往往缺乏真实感细节。2020年,来自加州大学伯克利分校、谷歌等机构的研究者提出了一种名为“神经辐射场”(Neural Radiance Fields, NeRF)的方法,彻底改变了这一领域。
NeRF的核心思想非常优雅:它不直接构建显式的3D网格或点云,而是用一个神经网络隐式地学习一个连续的3D场景表示。这个网络就像一个“魔法黑盒”,你只需要输入一组从不同角度拍摄的2D照片及其对应的相机参数,它就能学会整个3D空间的“样子”,并可以渲染出任意新视角下的逼真图像。

图1: NeRF的渲染效果(右)与真实照片(左)对比,展示了其惊人的真实感。 (图片来源: Mildenhall et al., ECCV 2020)
核心概念:什么是NeRF?
神经辐射场本质上是一个函数,它由多层感知机(MLP)参数化。这个函数将5D坐标作为输入,并输出该点的颜色和体积密度。
- 输入 (5D坐标):
- 空间位置 \((x, y, z)\)
- 观察方向 \((\theta, \phi)\),通常用3D向量 \((d_x, d_y, d_z)\) 表示。
- 输出:
- 体积密度 \(\sigma\):一个标量,表示该空间点被“占据”的可能性,与观察方向无关。
- RGB颜色 \((r, g, b)\):一个三维向量,表示从该观察方向看过去,该点的颜色。
用数学公式表示这个函数就是:
其中 \(\Theta\) 代表神经网络的权重参数。网络通过学习来逼近这个复杂的映射关系,从而编码了整个3D场景的光照、几何和材质信息。
工作流程:从输入到渲染
NeRF的工作流程可以分为训练和渲染两个阶段。
训练阶段
- 数据准备:收集一组同一静态场景的多视角2D图像,并精确标定每张图像的相机位姿(位置和朝向)。
- 射线投射:对于训练图像中的每个像素,根据相机模型生成一条从相机原点穿过该像素的3D射线。
- 采样与查询:沿着这条射线在近景和远景边界之间采样一系列3D点。将每个点的坐标和射线方向输入NeRF网络,得到该点的颜色和密度。
- 体渲染与损失计算:通过“体渲染”方程(见下一节)将这条射线上所有采样点的颜色和密度积分,合成该像素的预测颜色。然后与训练图像中该像素的真实颜色计算损失(如均方误差),并通过反向传播更新网络参数。
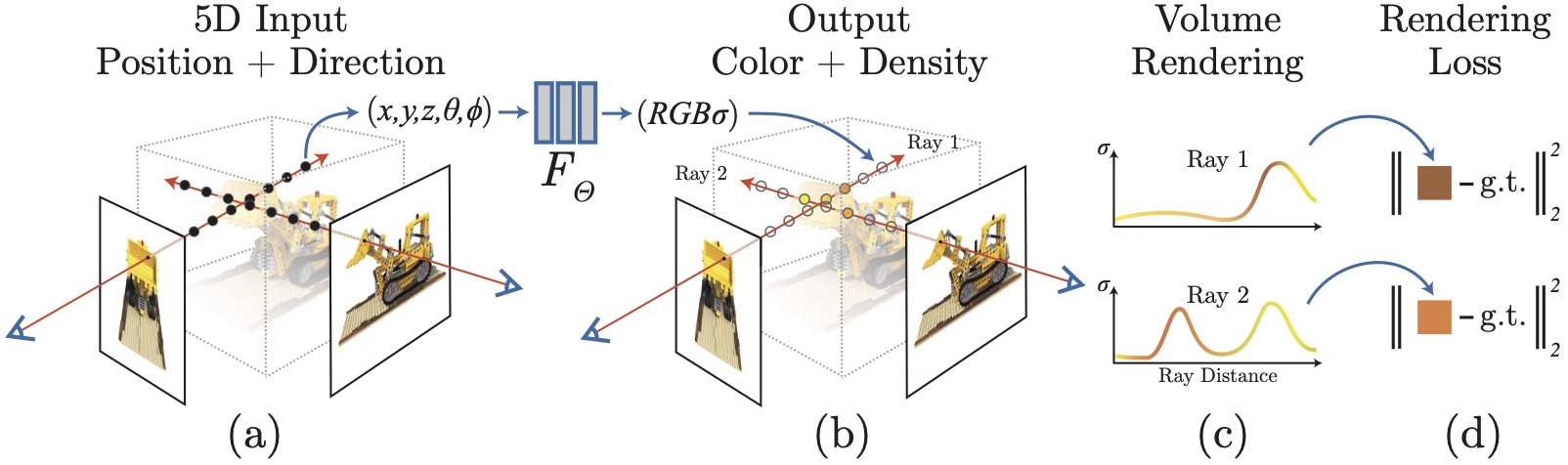
图2: NeRF工作流程示意图:沿着相机射线采样,通过MLP查询颜色和密度,最后通过体渲染合成像素颜色。(图片来源: Mildenhall et al., ECCV 2020)
渲染(推理)阶段
训练完成后,要渲染一个新视角的图像,只需指定该视角的相机参数,然后重复上述“射线投射 -> 采样查询 -> 体渲染”的过程,为虚拟相机图像平面的每个像素生成颜色即可。
体渲染:合成像素的关键
体渲染是连接离散采样点与最终2D图像的核心技术。它模拟了光线在参与性介质(如雾、云)中传播并累积颜色的物理过程。
对于一条射线 \(r(t) = o + t d\),其最终渲染颜色 \(C(r)\) 的计算公式为:
其中:
- \(t_n\) 和 \(t_f\) 是射线的近端和远端边界。
- \(\sigma(r(t))\) 和 \(c(r(t), d)\) 是网络在点 \(r(t)\) 处预测的密度和颜色。
- \(T(t)\) 是累积透射率,表示光线从 \(t_n\) 传播到 \(t\) 而没有击中任何粒子的概率:
在实际实现中,这个连续积分通过离散采样来近似计算。直观理解是:光线沿着射线前进,在密度高的地方(物体表面)会“吸收”更多该点的颜色,并阻止光线继续穿透,从而自然形成了物体的遮挡关系和外观。
位置编码:学习高频细节
研究者发现,如果将原始的 \((x, y, z)\) 坐标直接输入MLP,网络倾向于学习过于平滑的函数,导致渲染结果模糊,丢失高频的纹理和几何细节(如物体的边缘、花纹)。
为了解决这个问题,NeRF采用了一种称为“位置编码”或“正弦编码”的技巧。它将低维输入映射到更高维的空间,使MLP能够更容易地拟合高频变化。编码函数 \(\gamma\) 定义如下:
其中 \(p\) 是输入的一个标量分量(如 \(x\)),\(L\) 是编码的频率级别数量。这个操作将每个标量扩展为 \(2L\) 维的向量。在实践中,空间坐标 \((x,y,z)\) 和观察方向 \((d_x, d_y, d_z)\) 会分别经过不同 \(L\) 值的位置编码后再拼接起来输入网络。
这个简单的技巧对NeRF生成清晰、细节丰富的图像起到了至关重要的作用。
优势与挑战
主要优势
- 超高视觉质量:能够合成具有复杂光照、反射和半透明效果的逼真新视角图像,质量远超许多传统方法。
- 隐式连续表示:场景被表示为一个连续函数,理论上具有无限分辨率,避免了体素或网格表示中的离散化瑕疵。
- 输入简单:仅需要2D图像和相机参数,无需深度图、激光扫描等特殊硬件。
- 视角一致性:由于模型学习了整个3D空间的辐射场,其生成的所有新视角在几何和外观上都是严格一致的。
当前挑战
- 训练与渲染速度极慢:原始NeRF渲染一张图需要数分钟,训练一个场景需要数小时到数天。这是其最突出的瓶颈。
- 仅限静态场景:原始框架无法处理动态物体或场景变化。
- 对输入数据要求高:需要覆盖较全的多视角图像和精确的相机标定。遮挡严重或反射强烈的区域重建效果可能不佳。
- 编辑困难:由于是隐式表示,难以像操作网格一样对重建出的模型进行直接编辑。
代码实现核心
以下是使用PyTorch框架实现NeRF核心组件的一个高度简化的示例,展示了位置编码、网络前向传播和体渲染积分的核心思想。
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionalEncoder(nn.Module):
"""位置编码器"""
def __init__(self, L=10):
super().__init__()
self.L = L
def forward(self, x):
# x: [..., 1]
encodings = []
for i in range(self.L):
encodings.append(torch.sin(2**i * torch.pi * x))
encodings.append(torch.cos(2**i * torch.pi * x))
return torch.cat(encodings, dim=-1) # 输出维度: [..., 2*L]
class TinyNeRF(nn.Module):
"""一个极简的NeRF网络结构"""
def __init__(self, pos_L=10, dir_L=4, hidden_dim=256):
super().__init__()
# 位置编码后的维度: 3*2*pos_L = 60 (当pos_L=10时)
input_dim = 3 * 2 * pos_L
# 方向编码在中间层接入
dir_dim = 3 * 2 * dir_L
self.block1 = nn.Sequential(nn.Linear(input_dim, hidden_dim), nn.ReLU())
self.block2 = nn.Sequential(nn.Linear(hidden_dim, hidden_dim), nn.ReLU())
self.block3 = nn.Sequential(nn.Linear(hidden_dim, hidden_dim), nn.ReLU())
# 输出密度(标量)和中间特征
self.sigma_layer = nn.Linear(hidden_dim, 1)
self.feature_layer = nn.Linear(hidden_dim, hidden_dim)
# 将特征与编码后的方向结合,预测颜色
self.color_layer = nn.Sequential(
nn.Linear(hidden_dim + dir_dim, hidden_dim//2),
nn.ReLU(),
nn.Linear(hidden_dim//2, 3), # RGB
nn.Sigmoid() # 颜色值在0-1之间
)
def forward(self, x, d):
# x: 位置 [N, 3], d: 方向 [N, 3]
# 1. 位置编码和主干网络
encoded_x = self.positional_encode(x, self.pos_L)
h = self.block1(encoded_x)
h = self.block2(h) + h # 残差连接
h = self.block3(h)
# 2. 预测密度
sigma = F.relu(self.sigma_layer(h)) # 密度应为非负
# 3. 预测颜色(需要方向信息)
encoded_d = self.positional_encode(d, self.dir_L)
feature = self.feature_layer(h)
h_color = torch.cat([feature, encoded_d], dim=-1)
color = self.color_layer(h_color)
return color, sigma
def volume_rendering(sigmas, colors, t_vals):
"""离散体渲染积分"""
# sigmas, colors: [N_rays, N_samples, 1/3]
# t_vals: [N_samples],采样点的t值
deltas = t_vals[1:] - t_vals[:-1] # 计算采样区间长度
# 最后一个区间用一个大数填充
deltas = torch.cat([deltas, torch.tensor([1e10], device=deltas.device).expand(deltas[...,:1].shape)], dim=-1)
# 计算透射率 T_i 和权重 w_i
alpha = 1 - torch.exp(-sigmas * deltas.unsqueeze(-1)) # [N_rays, N_samples, 1]
exp_term = torch.exp(-torch.cumsum(sigmas * deltas.unsqueeze(-1), dim=1)) # 累积透射率
transmittance = torch.cat([torch.ones_like(exp_term[:,:1]), exp_term[:,:-1]], dim=1)
weights = transmittance * alpha # [N_rays, N_samples, 1]
# 加权求和得到最终像素颜色
rendered_color = torch.sum(weights * colors, dim=1) # [N_rays, 3]
return rendered_color, weights这段代码省略了数据加载、射线生成、分层采样(Hierarchical Sampling)和训练循环等复杂部分,但清晰地展示了NeRF模型架构和渲染算法的核心逻辑。