引言:从2D到3D的想象力飞跃
传统的3D建模和重建(如摄影测量、激光雷达)通常需要复杂的设备、专业的软件或大量的手动工作。有没有一种方法,能让AI像人类一样,仅仅通过观察几张不同角度的照片,就在脑海中构建出这个场景的完整3D模型,并可以自由地“想象”出从未拍摄过的新视角?
神经辐射场(Neural Radiance Fields, NeRF)的出现,让这个梦想照进现实。它代表了3D视觉领域的一次范式转移,将场景表示为一个由神经网络参数化的连续函数,开启了从稀疏2D输入生成高质量3D内容的新时代。

图1: NeRF从一组输入图像(左上)合成出平滑的新视角(动图展示)。(图片来源: Wikimedia Commons)
核心概念:什么是神经辐射场?
简单来说,NeRF是一个多层感知机(MLP)神经网络。它的输入是一个3D空间点的坐标 \((x, y, z)\) 和观察这个点的方向 \((\theta, \phi)\),输出是这个点的两个属性:
- 体积密度 (Volume Density, \(\sigma\)): 表示该点处存在几何实体的可能性(类似于不透明度)。
- 颜色 (RGB Color, \(\mathbf{c}\)): 表示从该观察方向看过去,该点反射出的颜色。
这个网络本身,就是整个3D场景的“数字孪生”。它不存储任何显式的网格或点云,而是将场景编码在其权重中。查询任何一个3D位置和视角,它都能告诉你那里“应该”是什么样子。
其中,\(\mathbf{x} = (x, y, z)\) 是空间坐标,\(\mathbf{d} = (\theta, \phi)\) 是观察方向,\(\Theta\) 是神经网络的参数。
工作流程:NeRF如何“渲染”一个像素?
要生成一张新视角的图片,NeRF需要为图片上的每一个像素进行计算,过程类似于计算机图形学中的光线追踪:
- 发射光线: 从新视角的相机中心,向图像平面上的一个像素点发射一条光线 \(\mathbf{r}(t) = \mathbf{o} + t\mathbf{d}\),其中 \(\mathbf{o}\) 是原点,\(\mathbf{d}\) 是方向。
- 采样点: 沿着这条光线,在一定的深度范围内(如从近平面 \(t_n\) 到远平面 \(t_f\))均匀或分层采样一系列3D点 \(\{\mathbf{x}_i\}\)。
- 网络查询: 将每个采样点的坐标 \(\mathbf{x}_i\) 和光线方向 \(\mathbf{d}\) 输入训练好的NeRF网络,得到该点的颜色 \(\mathbf{c}_i\) 和密度 \(\sigma_i\)。
- 体素渲染: 根据所有采样点的颜色和密度,通过体素渲染积分公式,合成出这条光线最终对应的像素颜色。
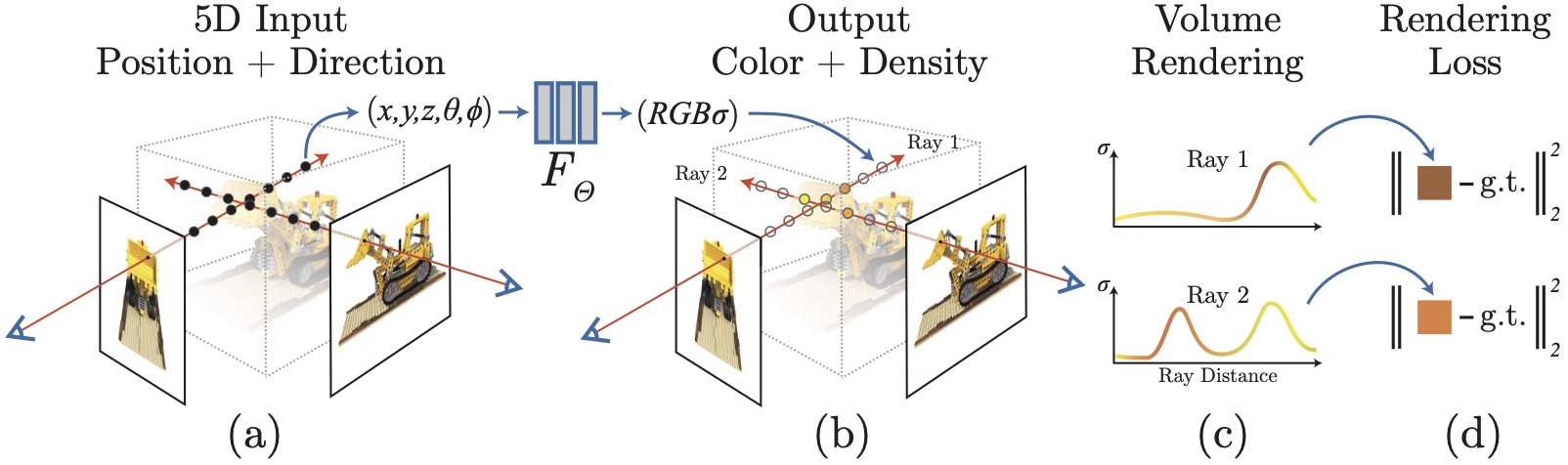
图2: NeRF渲染管线:沿相机光线采样,通过网络查询颜色和密度,最后积分得到像素颜色。(图片来源: NeRF原始论文)
位置编码:让网络理解3D空间
一个关键的发现是:直接将坐标 \((x, y, z)\) 输入普通的MLP,网络很难学习到高频的细节(如物体的纹理、边缘),输出结果往往过于平滑模糊。
NeRF的解决方案是使用位置编码(Positional Encoding)。它将低维的输入坐标映射到高维空间,使MLP能够更容易地拟合高频函数。公式如下:
其中 \(p\) 是归一化后的坐标值(如 \(x\)),\(L\) 是编码的频率数量。这个操作相当于让网络“看到”坐标在不同频率正弦波下的投影,极大地增强了其表示能力。
import torch
import torch.nn as nn
import numpy as np
def positional_encoding(x, L=10):
"""对输入张量x进行位置编码"""
encodings = [x]
for i in range(L):
encodings.append(torch.sin(2**i * np.pi * x))
encodings.append(torch.cos(2**i * np.pi * x))
return torch.cat(encodings, dim=-1)
# 示例:对一个3D坐标进行编码
coord = torch.tensor([0.1, 0.5, 0.9])
encoded_coord = positional_encoding(coord, L=6)
print(f"原始坐标维度: {coord.shape}, 编码后维度: {encoded_coord.shape}")体素渲染:从密度和颜色到图像
这是将沿光线的离散采样点聚合成一个像素颜色的核心步骤。其物理意义是:光线穿过半透明介质时,颜色会按介质的密度和颜色进行累积,同时光线本身会被介质阻挡而衰减。
对于一条光线,其最终颜色 \(C(\mathbf{r})\) 的计算公式为:
其中:
- \(\sigma_i, \mathbf{c}_i\) 是第 \(i\) 个采样点的密度和颜色。
- \(\delta_i = t_{i+1} - t_i\) 是相邻采样点之间的距离。
- \(T_i = \exp\left(-\sum_{j=1}^{i-1} \sigma_j \delta_j\right)\) 是透射率,表示光线成功到达第 \(i\) 个点而不被之前点阻挡的概率。
- \((1 - \exp(-\sigma_i \delta_i))\) 可以理解为第 \(i\) 个点对最终颜色的权重。
这个公式优雅地将神经网络预测的每个点的局部属性,通过物理上合理的积分,合成了全局的像素颜色。
优势与局限:NeRF的AB面
优势
- 超高视觉质量: 能合成具有复杂光照、反射和半透明效果的逼真新视角图像,细节丰富。
- 连续表示: 场景是无限分辨率的连续函数,可以任意放大和从任意角度观看,没有网格模型的“棱角”。
- 输入要求简单: 仅需要一组已知相机位姿的2D图像,无需3D监督信号(如点云、深度图)。
- 隐式压缩: 一个复杂的场景可以被压缩存储在一个相对较小的神经网络权重文件中。
局限与挑战
- 训练与渲染极慢: 训练一个场景需要数小时甚至数天;渲染一张图需要查询数百万个点,速度很慢。
- 静态场景假设: 经典NeRF只能处理静态场景,无法处理动态物体或场景变化。
- 编辑困难: 由于场景是隐式编码在权重中的,想要像编辑网格一样删除或移动一个物体非常困难。
- 对输入质量敏感: 需要准确的相机标定,且拍摄覆盖要全面,否则容易产生伪影。
代码一瞥:理解NeRF的核心循环
以下是NeRF前向传播中,沿一条光线进行渲染的核心逻辑的简化代码,帮助我们理解上述流程是如何在代码中实现的。
import torch
def render_rays(nerf_model, ray_origins, ray_directions, near, far, num_samples):
"""
渲染一批光线。
nerf_model: 训练好的NeRF网络模型
ray_origins: 光线原点 [batch_size, 3]
ray_directions: 光线方向(已归一化)[batch_size, 3]
"""
batch_size = ray_origins.shape[0]
# 1. 沿光线采样点
t_vals = torch.linspace(near, far, num_samples, device=ray_origins.device) # [num_samples]
# 添加随机扰动以进行分层采样(训练时)
# t_vals = t_vals + torch.rand_like(t_vals) * ((far - near) / num_samples)
# 采样点坐标: o + t * d
sample_points = ray_origins[:, None, :] + t_vals[None, :, None] * ray_directions[:, None, :] # [batch, num_samples, 3]
# 2. 展平以进行批量网络查询
flat_points = sample_points.reshape(-1, 3) # [batch*num_samples, 3]
flat_dirs = ray_directions[:, None, :].expand(-1, num_samples, -1).reshape(-1, 3) # [batch*num_samples, 3]
# 3. 对坐标和方向进行位置编码(此处省略编码函数)
# encoded_points = positional_encoding(flat_points)
# encoded_dirs = positional_encoding(flat_dirs)
# 4. 网络查询所有点的颜色和密度
# colors, densities = nerf_model(encoded_points, encoded_dirs) # 假设输出形状为 [batch*num_samples, 3], [batch*num_samples, 1]
colors = torch.rand(flat_points.shape[0], 3) # 模拟颜色
densities = torch.rand(flat_points.shape[0], 1) # 模拟密度
# 5. 体素渲染积分(简化版,未计算透射率T_i)
colors = colors.reshape(batch_size, num_samples, 3) # [batch, num_samples, 3]
densities = densities.reshape(batch_size, num_samples, 1) # [batch, num_samples, 1]
delta = t_vals[1:] - t_vals[:-1] # 采样间隔 [num_samples-1]
delta = torch.cat([delta, delta[-1:]], dim=0) # 填充最后一个间隔 [num_samples]
# 计算权重 (alpha) 和透射率 (T)
alpha = 1 - torch.exp(-densities * delta[None, :, None]) # [batch, num_samples, 1]
T = torch.cumprod(1 - alpha + 1e-10, dim=1) # 累积乘积计算透射率
T = torch.roll(T, shifts=1, dims=1) # 向右滚动一位,使T_i对应i-1之前的透射率
T[:, 0] = 1.0 # 第一个点的透射率为1
weights = T * alpha # [batch, num_samples, 1]
# 6. 加权求和得到最终像素颜色
pixel_colors = torch.sum(weights * colors, dim=1) # [batch, 3]
return pixel_colors
# 模拟数据
batch = 1024 # 一批光线的数量
nerf_model = None # 此处应为实际的模型
ray_o = torch.randn(batch, 3)
ray_d = torch.randn(batch, 3)
ray_d = ray_d / torch.norm(ray_d, dim=-1, keepdim=True) # 归一化方向向量
rendered_colors = render_rays(nerf_model, ray_o, ray_d, near=2.0, far=6.0, num_samples=64)
print(f"渲染了 {batch} 个像素,输出颜色张量形状: {rendered_colors.shape}")结论与展望
神经辐射场(NeRF)以其优雅的构思和惊艳的效果,为3D重建和生成领域打开了新的大门。它将场景表示为神经连续函数,实现了仅