引言:从2D到3D的想象力
想象一下,你手头只有几十张从不同角度拍摄的物体或场景照片。传统方法或许能拼出一个粗糙的3D模型,但细节往往丢失,看起来像低多边形游戏。而神经辐射场(Neural Radiance Fields, NeRF)的出现,彻底改变了游戏规则。它能够从这些稀疏的2D输入中,学习并重建出一个连续、高保真、且具备真实光影效果的3D场景,让你可以“走进”照片,从任意新视角观察,仿佛身临其境。

图1: NeRF的惊艳效果。左侧为输入的稀疏2D图像,右侧为模型合成的新视角画面,细节与光影极其逼真。(图片来源:NeRF原始论文)
核心思想:将场景编码为神经网络
NeRF的核心是一个多层感知机(MLP),即一个全连接神经网络。但这个网络学习的目标非常独特:它本身就是一个3D场景的数据库。
- 输入:一个3D空间点的坐标 \((x, y, z)\) 和观察这个点的方向 \((\theta, \phi)\)。
- 输出:该空间点在当前观察方向下的颜色 \((r, g, b)\) 和体密度 \(\sigma\)(可以理解为不透明度)。
用公式表示这个函数就是:
其中 \(F_{\Theta}\) 代表参数为 \(\Theta\) 的神经网络。一旦这个网络训练完成,它就“记住”了整个3D场景中每一点在不同角度看是什么样子。
工作流程:从光线到像素
要生成一张新视角的图片,NeRF模拟了相机成像的原理:从相机中心发射无数条光线,穿过每个像素,射入场景。
步骤分解
- 1. 发射光线:对于目标图像上的每一个像素,从相机位置 \(\mathbf{o}\) 沿视角方向 \(\mathbf{d}\) 发射一条光线 \(\mathbf{r}(t) = \mathbf{o} + t\mathbf{d}\)。
- 2. 采样点:沿着这条光线,在一定的深度范围内(如 \(t_n\) 到 \(t_f\))均匀或分层采样一系列3D点。
- 3. 查询网络:将每个采样点的坐标和光线方向输入训练好的NeRF网络,得到该点的颜色和密度。
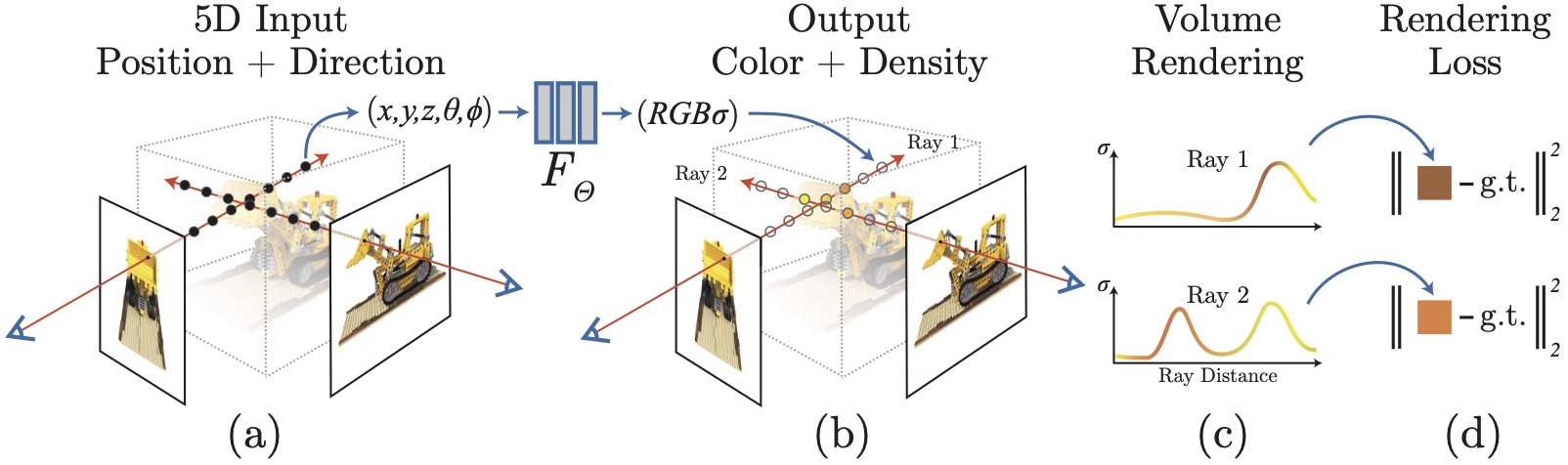
图2: NeRF工作流程示意图。相机发射光线,在光线上采样点,通过神经网络查询颜色和密度,最后通过体渲染合成像素颜色。(图片来源:NeRF原始论文)
体渲染:合成最终图像
得到了光线上所有采样点的颜色和密度后,如何合成这一个像素的最终颜色呢?这里用到了经典的体渲染方程。其思想是:光线在穿过场景时,颜色会像在雾中一样累积,同时会被遮挡。
像素颜色 \(C(\mathbf{r})\) 的计算公式如下:
其中:
- \(\mathbf{c}_i, \sigma_i\) 是第 \(i\) 个采样点的颜色和密度。
- \(\delta_i\) 是相邻采样点之间的距离。
- \(T_i = \exp(-\sum_{j=1}^{i-1} \sigma_j \delta_j)\) 是累积透射率,表示光线到达第 \(i\) 个点之前没有被阻挡的概率。
- \((1 - \exp(-\sigma_i \delta_i))\) 可以看作是第 \(i\) 个点对最终颜色的贡献权重。
这个可微分的渲染过程是NeRF能够被训练的关键。训练时,通过比较渲染出的图像与输入的真实图像之间的差异(如MSE损失),反向传播来优化神经网络参数 \(\Theta\)。
NeRF的魔力与优势
- 超高视觉质量:能够合成具有复杂细节、逼真反射和精细阴影的新视图,质量远超传统多视图立体(MVS)方法。
- 连续场景表示:神经网络是一个连续函数,因此可以生成任意分辨率、任意视角的图像,没有离散体素或网格的“阶梯”效应。
- 隐式压缩:一个复杂的3D场景最终被压缩存储在一个相对较小的神经网络权重文件中。
- 输入要求简单:仅需要一组带有相机位姿的2D图像,无需昂贵的3D扫描设备或复杂的预处理。
面临的挑战与局限
- 训练与渲染极慢:原始NeRF训练一个场景需要数小时甚至数天,渲染一张新图也需要数十秒。这是因为每条光线需要查询数百次网络。
- 对输入数据敏感:需要精确的相机参数(位姿)。如果位姿不准,重建质量会急剧下降。
- 处理动态场景困难:原始NeRF假设场景是静态的,无法直接处理运动物体或变化的光照。
- 编辑性差:场景知识被编码在神经网络权重中,难以像操作网格模型一样进行局部编辑。
未来展望与衍生方向
自2020年提出以来,NeRF社区蓬勃发展,出现了大量改进和变体:
- 加速方向:如 Instant-NGP(Instant Neural Graphics Primitives)利用哈希编码和多分辨率网格,将训练时间从小时级缩短到分钟级,实现了实时渲染。
- 动态NeRF:引入时间维度或变形场,用于重建非刚性物体、人脸表情或整个动态事件。
- 生成式NeRF:将NeRF与生成对抗网络(GAN)结合,从单张图片或文本描述中生成3D内容,如DreamFusion。
- 大规模场景重建:将NeRF应用于城市街区、室内建筑等大规模场景的重建与导航。
以下是一个高度简化的NeRF查询函数的PyTorch示意代码,展示了核心思想:
import torch
import torch.nn as nn
class TinyNeRF(nn.Module):
def __init__(self):
super().__init__()
# 一个极简的MLP网络
self.net = nn.Sequential(
nn.Linear(3 + 3, 256), # 输入:3D坐标 + 3D方向
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 4) # 输出:RGB(3) + 密度(1)
)
def forward(self, xyz, dir):
# 将坐标和方向信息拼接后输入网络
input_vec = torch.cat([xyz, dir], dim=-1)
output = self.net(input_vec)
rgb = torch.sigmoid(output[..., :3]) # 颜色在0-1之间
sigma = torch.relu(output[..., 3:]) # 密度为非负
return rgb, sigma
# 实例化模型
model = TinyNeRF()
# 假设我们有一个采样点的坐标和方向
sample_xyz = torch.randn(1, 3)
sample_dir = torch.randn(1, 3)
color, density = model(sample_xyz, sample_dir)
print(f"Predicted Color: {color}, Density: {density}")结语
神经辐射场(NeRF)不仅仅是一个优秀的3D重建工具,它更代表了一种全新的场景表示范式——用神经网络作为场景的“描述语言”。它巧妙地将计算机图形学中的体渲染与深度学习的表示能力相结合,打开了通往高保真神经渲染世界的大门。
尽管在速度、编辑性等方面仍有局限,但其核心思想已催生出一个庞大而活跃的研究领域。从影视特效、虚拟现实到机器人视觉、文化遗产数字化,NeRF及其衍生技术正在不断拓展其应用边界,让我们对未来数字世界的构建方式充满期待。