引言
注意力机制是深度学习领域的重要突破,它模仿人类认知过程中的注意力分配机制,让模型能够有选择地关注输入数据中的重要部分。这一概念最初在机器翻译任务中被提出,现已广泛应用于各种AI任务。
本文将介绍注意力机制的发展历程:
- Seq2Seq模型 - 注意力机制的前身
- 注意力机制原理 - 核心数学公式
- 自注意力机制 - Transformer的基础
- Transformer架构 - 现代NLP的基石
理解注意力机制对于掌握现代深度学习模型至关重要,它是BERT、GPT等先进模型的核心组件。
Seq2Seq模型
Seq2Seq(Sequence to Sequence)模型是处理序列到序列转换任务的基础架构,由编码器和解码器组成。编码器将输入序列编码为固定长度的上下文向量,解码器基于该向量生成输出序列。
模型结构
传统的Seq2Seq模型使用RNN或LSTM作为基础单元:
class Seq2Seq(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.encoder = nn.LSTM(input_dim, hidden_dim)
self.decoder = nn.LSTM(hidden_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, src, trg):
# 编码器处理输入序列
_, (hidden, cell) = self.encoder(src)
# 解码器基于编码器状态生成输出
outputs, _ = self.decoder(trg, (hidden, cell))
return self.fc(outputs)优缺点
- 优点:能够处理变长序列,适用于翻译、摘要等任务
- 缺点:信息瓶颈问题,长序列信息丢失,梯度消失

图1: Seq2Seq模型的基本架构,包含编码器和解码器
注意力机制原理
注意力机制解决了Seq2Seq模型的信息瓶颈问题,允许解码器在生成每个输出时访问编码器的所有隐藏状态,而不仅仅是最后一个状态。
注意力计算
注意力权重的计算公式:
其中,\( e_{ij} = a(s_{i-1}, h_j) \) 是注意力得分函数,\( s_{i-1} \) 是解码器上一个时间步的隐藏状态,\( h_j \) 是编码器第j个时间步的隐藏状态。
上下文向量
上下文向量是编码器隐藏状态的加权和:

图2: 注意力权重示意图,显示解码时对输入不同部分的关注程度
自注意力机制
自注意力机制(Self-Attention)是注意力机制的扩展,允许序列中的每个位置关注序列中的所有位置,从而捕捉序列内部的依赖关系。
查询-键-值模型
自注意力使用查询(Query)、键(Key)、值(Value)三元组:
其中,\( d_k \) 是键向量的维度,用于缩放点积结果。
多头注意力
多头注意力允许模型同时关注来自不同表示子空间的信息:
每个注意力头:\( \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \)
优缺点
- 优点:长距离依赖建模,并行计算,可解释性强
- 缺点:计算复杂度高,内存消耗大
Transformer架构
Transformer是基于自注意力机制的序列到序列模型,完全摒弃了循环和卷积结构,成为现代NLP的基础架构。
编码器结构
每个编码器层包含:
- 多头自注意力机制
- 前馈神经网络
- 残差连接和层归一化
解码器结构
解码器在自注意力层添加了掩码机制,防止当前位置关注未来位置的信息。
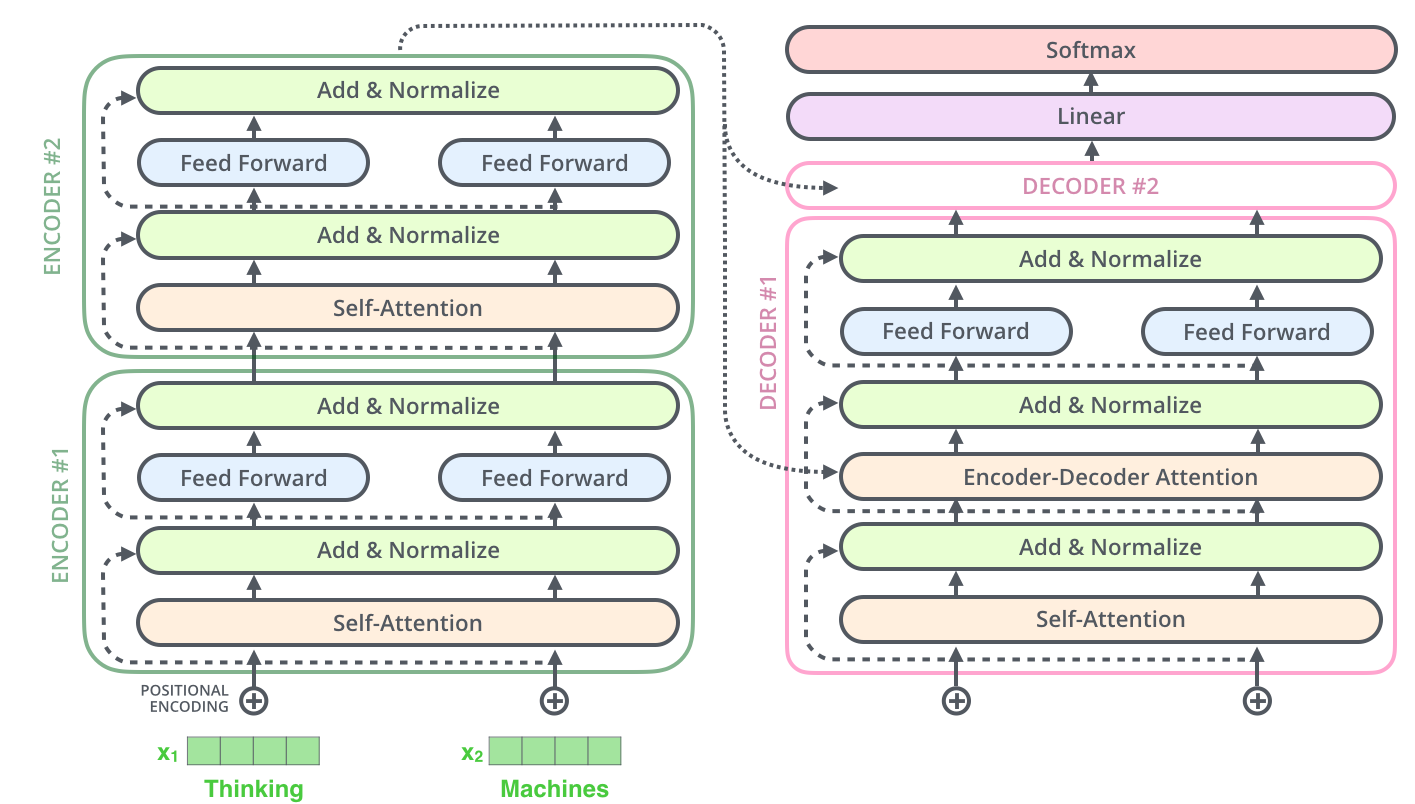
图3: Transformer模型的完整架构,显示编码器和解码器的堆叠结构
位置编码
由于Transformer不包含循环结构,需要位置编码来注入序列的顺序信息:
代码实现
下面使用PyTorch实现一个简化的自注意力机制:
import torch
import torch.nn as nn
import math
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super().__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 分割为多头
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# 计算注意力分数
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values])
out = out.reshape(N, query_len, self.heads * self.head_dim)
return self.fc_out(out)Transformer层实现
完整的Transformer编码器层实现:
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super().__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
# 残差连接和层归一化
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out应用场景
注意力机制和Transformer架构已在多个领域取得突破性进展:
自然语言处理
- 机器翻译 - BERT、GPT系列模型
- 文本摘要 - 基于注意力的抽象式摘要
- 问答系统 - 注意力帮助模型关注相关文本片段
计算机视觉
- Vision Transformer - 将图像分割为补丁序列
- 目标检测 - DETR模型使用Transformer进行检测
- 图像生成 - 注意力机制在GAN中的应用
多模态任务
- 图像描述生成 - 结合视觉和语言注意力
- 视觉问答 - 同时处理图像和文本信息
- 语音识别 - 音频序列的注意力建模

图4: BERT模型基于Transformer编码器,在多个NLP任务中表现出色
结论
注意力机制从解决Seq2Seq模型的信息瓶颈问题开始,发展到自注意力机制,最终催生了革命性的Transformer架构。这一演进过程深刻改变了深度学习的发展方向。
关键进展包括:
- 从固定长度上下文向量到动态注意力权重
- 从序列顺序处理到并行计算
- 从特定领域应用到通用架构设计
注意力机制的成功证明了模仿人类认知过程的有效性,为构建更智能的AI系统提供了重要启示。未来,注意力机制可能会在更多领域发挥作用,推动AI技术的进一步发展。