引言
Transformer架构最初在自然语言处理领域取得了巨大成功,但近年来在计算机视觉任务中也展现出惊人潜力。传统的卷积神经网络(CNN)虽然有效,但在处理长距离依赖关系方面存在局限。
Vision Transformer(ViT)的提出标志着计算机视觉领域的重要转折点,它通过自注意力机制实现了全局上下文信息的有效捕捉。
- 2020年,Vision Transformer首次在图像分类任务上超越CNN
- ViT在多个视觉基准测试中刷新记录
- Transformer架构为多模态学习提供了统一框架
Transformer基础
Transformer架构的核心是自注意力机制,它允许模型在处理序列数据时关注所有位置的信息。
编码器-解码器结构
标准Transformer包含编码器和解码器堆栈,每个层都有多头自注意力机制和前馈神经网络。
其中Q、K、V分别代表查询、键和值矩阵,\(d_k\)是键向量的维度。
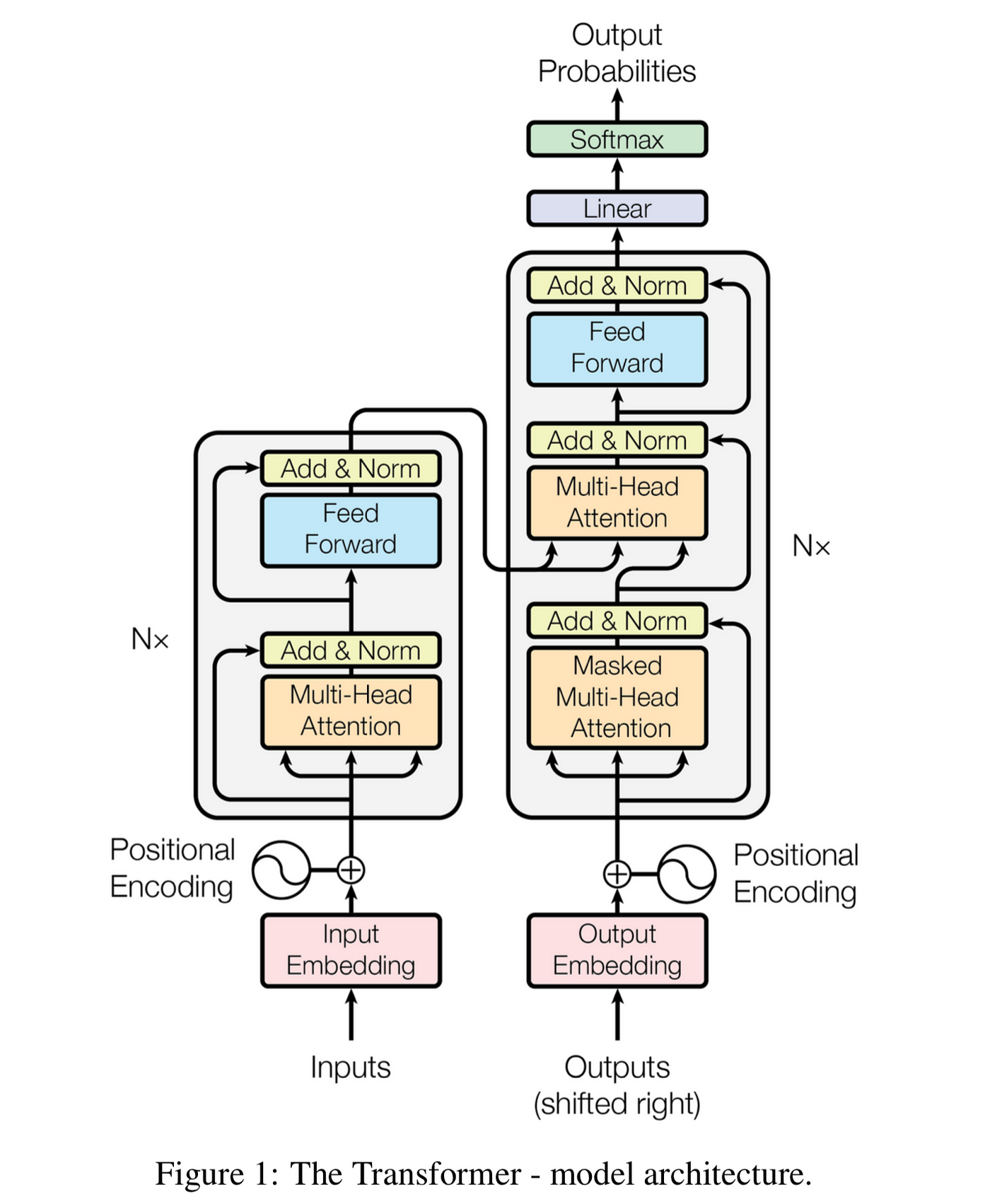
图1: Transformer架构的基本组成
Vision Transformer
Vision Transformer将图像分割成固定大小的patch,然后将这些patch线性嵌入成序列,作为Transformer的输入。
图像分块处理
给定输入图像\(x \in \mathbb{R}^{H \times W \times C}\),将其分割成N个patch:
其中P是patch大小,N = HW/P²是patch数量。

图2: Vision Transformer的图像分块处理流程
自注意力机制
自注意力机制是Transformer的核心,它计算输入序列中每个位置与其他所有位置的相关性。
多头注意力
多头注意力允许模型同时关注不同表示子空间的信息:
这种设计增强了模型的表示能力,使其能够捕捉不同类型的依赖关系。
- 每个注意力头学习不同的关注模式
- 多头机制提高了模型的表达能力
- 并行计算提高了训练效率
应用领域
Vision Transformer在多个计算机视觉任务中表现出色:
图像分类
ViT在ImageNet等大型图像分类数据集上达到了state-of-the-art性能。
目标检测
DETR(Detection Transformer)将目标检测视为集合预测问题,消除了传统方法中的锚框设计。
语义分割
SETR等模型使用Transformer进行像素级分类,在分割任务中取得优异效果。

图3: Vision Transformer在各类视觉任务中的应用示例
代码实现
下面使用PyTorch实现一个简化的Vision Transformer:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(in_chans, embed_dim,
kernel_size=patch_size,
stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, E, H/P, W/P)
x = x.flatten(2) # (B, E, N)
x = x.transpose(1, 2) # (B, N, E)
return xclass MultiHeadAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x与传统CNN对比
Vision Transformer与卷积神经网络在多个方面存在显著差异:
优势
- 全局感受野:自注意力机制可以捕捉图像中任意两个位置的关系
- 更好的可扩展性:模型性能随数据量和模型规模的增长而持续提升
- 统一架构:为多模态任务提供了统一的框架
挑战
- 数据需求:需要大量训练数据才能发挥优势
- 计算复杂度:自注意力的计算复杂度随序列长度平方增长
- 位置编码:需要显式的位置信息编码

图4: Vision Transformer与CNN在不同数据量下的性能对比
结论
Vision Transformer代表了计算机视觉领域的重要进步,它打破了传统CNN的局限,为视觉理解任务提供了新的范式。
关键要点:
- Transformer架构在视觉任务中展现出强大潜力
- 自注意力机制提供了全局上下文理解能力
- ViT在大规模数据集上表现优异
- 未来的研究方向包括效率优化和多模态融合
随着计算资源的增长和算法的优化,Transformer架构有望在更多视觉任务中发挥重要作用,推动人工智能技术的进一步发展。